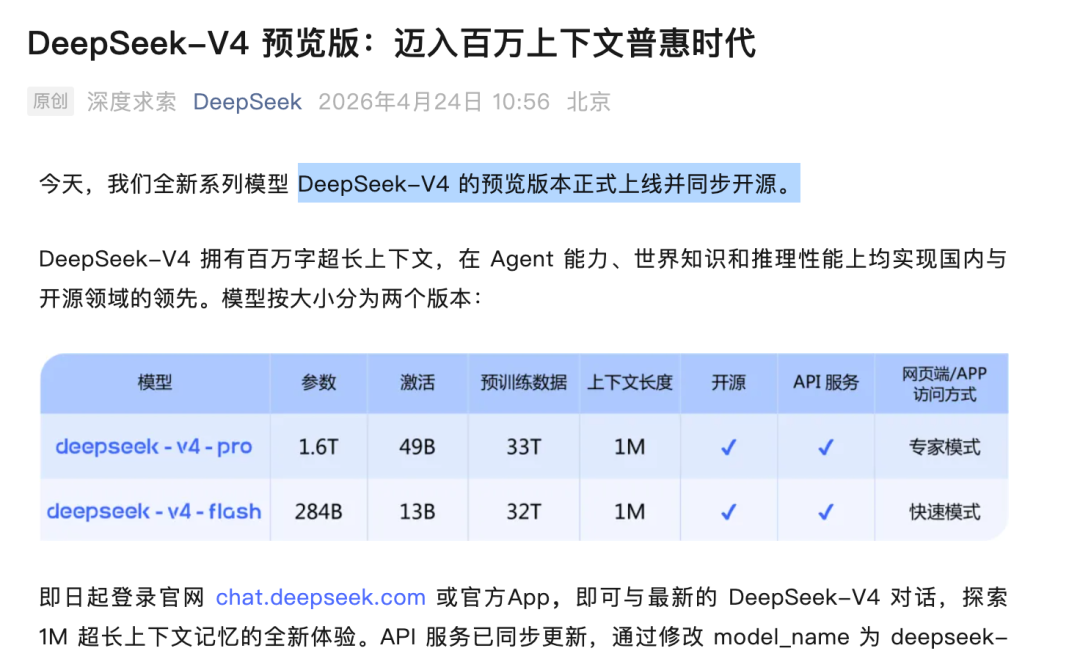
就在今天,DeepSeek 团队发布了备受期待的 DeepSeek-V4 系列——包括 1.6T 总参数的 V4-Pro 和 284B 的 V4-Flash,两款模型均原生支持 100 万 token 的超长上下文,且已完全开源。
这不是一次简单的版本迭代。DeepSeek-V4 用三项架构创新彻底改写了开源模型的效率天花板:混合注意力(CSA+HCA) 将长文本推理的 KV Cache 压缩至 DeepSeek-V3.2 的 10%(V4-Pro)甚至 7%(V4-Flash);Manifold-Constrained Hyper-Connections 让数百层网络的训练稳定性大幅提升;Muon 优化器则带来了比 AdamW 更快的收敛速度。
性能上,DeepSeek-V4-Pro-Max 在知识、推理、代码等多项基准上 追平甚至超越 GPT-5.4 和 Gemini-3.1-Pro,Codeforces 评分与 GPT-5.4 持平,中文写作和白领任务表现尤其亮眼。这意味着,开源模型首次在高难度任务上与闭源顶尖模型站到了同一水平线。
国家 AI 战略:从“鼓励发展”到“人才紧缺”
DeepSeek-V4 的发布不是孤立的技术事件。它背后是国家对人工智能产业的持续重注——从《新一代人工智能发展规划》到各地政府对 AI 算力、算法、数据要素的专项扶持,AI 已成为数字经济时代的核心驱动力。
然而,尖端模型不断涌现的另一面是:合格的 AI 人才,尤其是大模型工程与应用方向的人才,严重供不应求。 大厂开出的百万年薪、中小企业的转型焦虑、传统 IT 人员的职业迷茫——这些都指向同一个问题:如何系统、高效地掌握大模型从原理到落地的全链路技能?
真术相成:不止于大模型,一套完整的 AI 实战课程
如果你正在考虑转行 AI,或者希望将大模型能力融入现有技术栈,真术相成的《AI算法培训班》正是为你设计的。课程覆盖了从理论基础到企业级项目交付的完整路径:
基础认知:人工智能发展史、Transformer 网络结构、注意力机制(含 MQA、GQA、MLA 等最新变体)、KV Cache、RoPE、FlashAttention 等核心原理拆解。
微调与部署:高效微调(LoRA/QLoRA/Unsloth/LLaMA-Factory/XTuner)、deepspeed 分布式训练、推理框架(LMDeploy、VLLM)、模型量化与部署。
工具与框架:HuggingFace/ModelScope 生态、LangChain/LangGraph、Dify 工作流、Ollama 本地部署、MCP 协议应用。
评估与蒸馏:OpenCompass 评估体系、模型蒸馏实战、miniMind 小模型训练。
企业级项目:结构化提示词工程、智能客服机器人、Agent 小游戏、MySQL 数据库智能代理、长篇故事生成机器人、Muti-Agents 协作,以及 手搓 OpenClaw、TradingAgent 实盘对接、小术助手数智引力等真实场景案例。
“真术相成的课程不止于大模型。我们的大模型应用与原理方向——覆盖 Transformer、微调、部署、Agent 开发等——只是整个课程体系的一个模块。在此之前,你还需要打好编程的学习基础;在此之后,还有项目实战和就业指导。我们提供的是一条从零到就业的完整学习路径,大模型是其中的重要一环,但不是唯一的一环。”

无论你是 IT 从业者想转战大模型,还是理工科学生希望系统入行,真术相成都提供了经过验证的实战体系。
最后:
DeepSeek-V4 的开源,再一次降低了顶尖大模型的使用门槛。但工具越强大,使用工具的人就越需要系统、正确的知识体系。国家 AI 战略的号角已经吹响,人才缺口就是你的机会窗口。
真术相成的大模型课程,只是这条路上的一个加速器。如果你准备好了,不妨从这里开始。
课程详情与试听,欢迎访问真术相成官网或咨询课程顾问。
Copyright © 2022 真术相成 ・ 蜀ICP备2022001576号  川公网安备 51019002005104号
川公网安备 51019002005104号
